New Features - Prisma AIRS - October 2025
Automated AI Red Teaming
Palo Alto Networks' Prisma AIRS AI Red Teaming is an automated solution designed to scan any AI system —including LLMs and LLM-powered applications—for safety and security vulnerabilities.
The tool performs a Scan against a specified Target (model, application, or agent) by sending carefully crafted attack prompts to simulate real-world threats. The findings are compiled into a comprehensive Scan Report that includes an overall Risk Score (ranging from 0 to 100), indicating the system's susceptibility to attacks.
Prisma AIRS offers three distinct scanning modes for thorough assessment:
Attack Library Scan: Uses a curated, proprietary library of predefined attack scenarios, categorized by Security (e.g., Prompt Injection, Jailbreak), Safety (e.g., Bias, Cybercrime), and Compliance (e.g., OWASP LLM Top 10).
Agent Scan: Utilizes a dynamic LLM attacker to generate and adapt attacks in real-time, enabling full-spectrum Black-box, Grey-box, and White-box testing.
Custom Attack Scan: Allows users to upload and execute their own custom prompt sets alongside the built-in library.
A key feature of the service is its single-tenant deployment model, which ensures complete isolation of compute resources and data for enhanced security and privacy.
MCP Threats Detection
Prisma AIRS protects your AI agents from supply chain attacks by adding support for Model Context Protocol (MCP) tools. This feature adds security scanning capabilities to the MCP ecosystem, specifically targeting two critical threats:
- Context poisoning via tool definition, tool input (request) and tool output (response) manipulation. This prevents malicious actors from tampering with MCP tool definitions that could trick AI agents into performing harmful actions like leaking sensitive data or executing dangerous commands.
- Exposed credentials and identity leakage. This detects and blocks sensitive data (tokens, credentials, API keys) from being exposed through MCP tool interactions.
This functionality provides a number of benefits:
- Zero-touch security. No new UI or profile configuration required.
- Comprehensive threat detection. Leverages existing detection services (DLP, prompt injection, toxic content, etc.).
- Real-time protection. Works with both synchronous and asynchronous scanning APIs.
- Supply chain security. Validates tool descriptions, inputs and outputs as part of MCP communication.
It ensures that as AI agents become more powerful and autonomous through MCP tools, they cannot be weaponized against your organization through compromised or malicious tools in the MCP ecosystem.
This feature represents a broader initiative to secure AI agents that use MCP for tool integration, ensuring that MCP-based AI systems remain secure against manipulation and data exposure attacks. For more information, Detect MCP Threats.
Secure AI Models with AI Model Security
Models serve as the foundation of AI/ML workloads and power critical systems across organizations today. Prisma AIRS now features AI Model Security, a comprehensive solution that ensures only secure, vulnerability-free models are used while maintaining your desired security posture.
AI/ML models pose significant security risks as they can execute arbitrary code during loading or inference. This is a critical vulnerability that existing security tools fail to adequately detect. Compromised models have been exploited in high-impact attacks including cloud infrastructure takeovers, sensitive data theft, and ransomware deployments. Your valuable training datasets and inference data processed by these models make them prime targets for cybercriminals seeking to infiltrate AI-powered systems.
What you can do with AI Model Security :
- Model Security Groups —Create Security Groups that apply different managed rules based on where your models come from. Set stricter policies for external sources like HuggingFace, while tailoring controls for internal sources like Local or Object Storage.
- Model Scanning —Scan any model version against your Security Group rules. Get clear pass/fail results with supporting evidence for every finding, so you can confidently decide whether a model is safe to deploy.
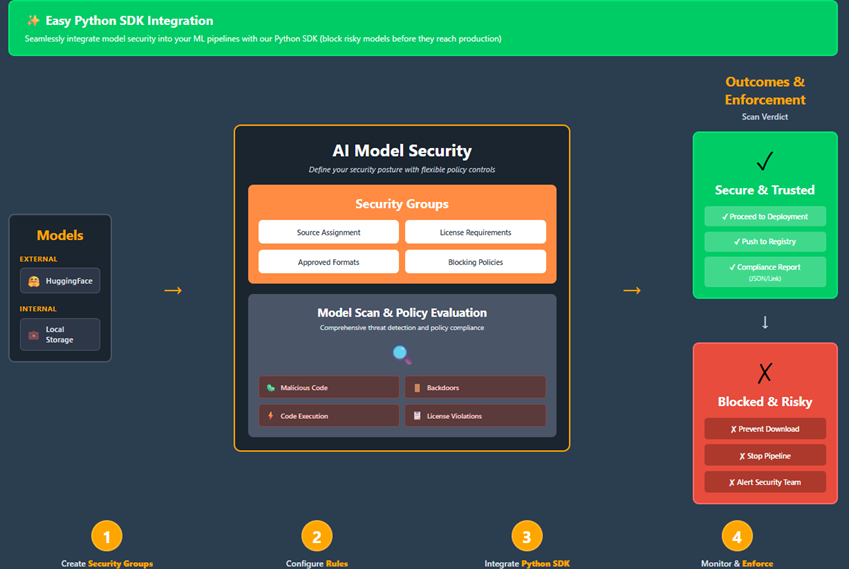
- Prevent Security Risks Before Deployment: Identify vulnerabilities, malicious code, and security threats in AI models before they reach production environments.
- Enforce Consistent Security Standards: Apply organization-wide security policies across all model sources, ensuring every model meets your requirements regardless of origin.
- Accelerate Secure AI Adoption: Reduce manual security review time with automated scanning, enabling teams to deploy models faster without compromising security.
- Maintain Compliance and Governance: Demonstrate security due diligence with detailed scan evidence and audit trails for regulated industries and internal compliance requirements.