Enterprise DLP
About Enterprise DLP
Table of Contents
About Enterprise DLP
Enterprise Data Loss Prevention (E-DLP) is a set of tools and processes to protect sensitive information from exfiltration.
On May 7, 2025, Palo Alto Networks is introducing new Evidence Storage and Syslog Forwarding service IP
addresses to improve performance and expand availability for these services
globally.
You must allow these new service IP addresses on your network
to avoid disruptions for these services. Review the Enterprise DLP
Release Notes for more
information.
| Where Can I Use This? | What Do I Need? |
|---|---|
|
Or any of the following licenses that include the Enterprise DLP license
|
Enterprise Data Loss Prevention (E-DLP) is a cloud-based service consisting of a set of tools and processes that enable you to protect sensitive information against unauthorized access, misuse, extraction, or sharing. Enterprise DLP uses supervised machine learning algorithms to sort sensitive documents into Financial, Legal, Healthcare, and other categories for document classification to guard against exposures, data loss, and data exfiltration. These patterns can identify the sensitive information in traffic flowing through your network and protect them from exposure.
Enterprise DLP allows you to protect sensitive data in the following ways:
- Prevent uploads and downloads of file and non-file based traffic from leaking to unsanctioned web apps—Discover and conditionally stop sensitive data leaks to untrusted web apps.
- Monitor uploads and downloads to sanctioned web apps—Discover and monitor sensitive data when it’s uploaded to sanctioned corporate apps.
To help you inspect content and analyze the data in the correct context so that you can accurately identify sensitive data and secure it to prevent incidents, Enterprise DLP is enabled through a cloud service. Enterprise DLP supports over 1,000 predefined data patterns and 20 predefined data profiles. Enterprise DLP is designed to automatically make new patterns and profiles available to you for use in Security policy rules as soon they’re added to the cloud service.
- Data Patterns—Help you detect sensitive content and how that content is being shared or accessed on your network.Predefined data patterns and built-in settings make it easy for you to protect data that contain certain properties (such as document title or author), credit card numbers, regulated information from different countries (such as driver’s license numbers), and third-party DLP labels. To improve detection rates for sensitive data in your organization, you can supplement predefined data patterns by creating custom data patterns that are specific to your content inspection and data protection requirements. In a custom data pattern, you can also define regular expressions and data properties to look for metadata or attributes in the file’s custom or extended properties and use it in a data profile.
- Data Profiles—Power the data classification and monitor capabilities available on your managed firewalls to prevent data loss and mitigate business risk.Data profiles are a collection of data patterns used to scan for a specific object or type of content. To perform content analysis, the predefined data profiles have data patterns that include industry-standard data identifiers, keywords, and built-in logic in the form of machine learning, regular expressions, and checksums for legal and financial data patterns. When you use the data profile in a Security policy rule, the firewall can inspect the traffic for a match and take action.After you use the data patterns (either predefined or custom), you manage the data profiles from the Panorama® management server or Strata Cloud Manager. You can use a predefined data profile, or create a new profile, and add data patterns to it. You then create security policies and apply the profiles you added to the policy rules you create. For example, if a user uploads a file and data in the file matches the criteria in the policy rules, the managed firewall either creates an alert notification or blocks the file upload.
Enterprise DLP generates a DLP incident when traffic matches a data profile associated with a Security policy rule. The log entry contains detailed information regarding the traffic that matches one or more data patterns in the data profile. The log details enable forensics by enabling you to verify when a matched data generated an alert notification or when Enterprise DLP blocks traffic.
You can view the snippets in the data filtering logs. By default, data masking partially masks the snippets to prevent the sensitive data from exposure. You can completely mask the sensitive information, unmask snippets, or disable snippet extraction and viewing.
Data Classification with Large Language Models (LLM) and Context-Aware Machine Learning
Sensitive data exfiltration can manifest in diverse formats and traverses numerous channels within an organization's infrastructure. Traditional data loss prevention solutions adopt a one-size-fits-all approach to preventing exfiltration of sensitive data that often proves insufficient for organizations aiming to ensure comprehensive security. This creates noise and distraction; impacting your security administrators' ability to investigate and resolve real security incidents when they occur.
Enterprise DLP uses a various artificial intelligence (AI) and machine learning (ML) driven methods to improve detection accuracy for different file formats and techniques.
- Regex Data Patterns Enhanced With Large Language Models (LLM) and ML Models to Improve Detection AccuracyEnterprise DLP augments data patterns traditionally reliant on regular expression matching with ML classifiers. These data patterns undergo training using diverse data sets, using LLMs to establish ground truth. This integration significantly enhances accuracy and reduces false positives across 350+ classifiers to detect PII, GDPR, Financial, and many other categories. Predefined regex data patterns enhanced with ML capabilities marked as Augmented with ML. Additionally, users can report false positive detections against the DLP incident where the false positive detection occurred to facilitate model retraining for improved accuracy.For example, patterns like credit card numbers or bank account numbers can vary in length and pose a challenge for strict content-matching approaches, often yielding to a large number of false positive detections. In such cases all pattern matches, such as the detection of a 12-digit credit card number, undergo further processing by specialized ML models designed to comprehend the context of sensitive data occurrences. LLMs enable the generation of high-quality training and testing data, resulting in best-in-class detection accuracy.
- Predefined AI-Powered Document and Image ClassifiersEnterprise DLP uses Deep Neural Network (DNN) based document classifiers to interpret the semantics of inspected documents to analyze their context and accurately classify them across financial, healthcare, legal, and source code categories of documents across all potential data loss vectors. When you enable Optical Character Recognition (OCR) you can use the predefined data patterns that are Augmented with ML, which use DNN-based models for image classification, to immediately start driving better detection accuracy across categories such as Driver’s Licenses, Passports, and National ID to protect sensitive information.
- Train Your Own AI-Powered ML ModelsYour organization might have customized documents that pose a significant risk of exfiltration. For example, Merger & Acquisition documents or proprietary source code might demand unique detection models specific to your organization. Enterprise DLP lets you train your own AI model by uploading custom document types. This enables your organization to curate an ML detection model that accurately identifies documents specific to your organization. This privacy-preserving algorithm ensures that your sensitive information isn't used to train any predefined AI-powered document type detections. All custom documents you upload to Enterprise DLP, and subsequent training of the AI-powered ML model, are specific and unique to your organization.
Additional Detection Accuracy
To further improve detection accuracy and reduce false positives, you can also specify:
- Basic and Weighted Regular Expressions—A regular expression (regex) describes how to search for a specific text pattern and then display the match occurrences when a pattern match is found. There are two types of regular expressions—basic and weighted.
- A basic regular expression searches for a specific text pattern. When a pattern match is found, the service displays the match occurrences.
- A weighted regular expression assigns a score to a text entry. When the score threshold is exceeded, the service returns a match for the pattern.To reduce false-positives and maximize the search performance of your regular expressions, you can assign scores using the weighted regular expression builder when you create data patterns to find and calculate scores for the information that’s important to you. Scoring applies to a match threshold, and when a score threshold is exceeded, such as enough expressions from a pattern match an asset, the asset will be indicated as a match for the pattern.For more information, including a use case and best practices, see Configure Regular Expressions.
- Proximity Keywords—Enterprise DLP uses proximity keywords to improve the confidence level of detections. Enterprise DLP assigns a detection a High confidence level if the data pattern's proximity keywords is in the vicinity of the detected regex. Proximity keywords are not case-sensitive and multiple proximity keywords can be specified for a single data pattern. Enterprise DLP uses the following approach to determine if a keyword is in proximity to the expression.Enterprise DLP considers whether keyword is in proximity key if:
- The end of the keyword is less than or equal to 200 characters of the start of the matched expression, or
- The start of the keyword is less than or equal to 200 characters after the end of the matched expression
For example, consider a file containing a 9-digit number detected near a SSN proximity keyword. In this case, it's more than likely that the 9-digit number is a valid social security number. Conversely, if SSN is included in the document title and a 9-digit number appears a few pages into the document, it's less likely to be relevant. - Confidence Levels—The confidence level reflects how confident Enterprise DLP is when detecting matched traffic. Enterprise DLP determines the confidence level by inspecting the distance of regular expressions to proximity keywords.
- Low—Matches on regex detections only.
- Medium—Matches on regex detections and checksum validations if applicable (for example, credit cards).
- High—Matches on regex detections and checksum validation if applicable. Enterprise DLP considers detections as High Confidence if the proximity keyword is within 200 characters of the regular expression match.
Additionally, custom data patterns that don't include any proximity keywords to identify a match always have both Low and High confidence level detections.
Structured Data
Enterprise DLP focuses on the actual data within structured documents to prevent exfiltration of sensitive data rather than relying on headers to identify whether data is sensitive or not. This enables Enterprise DLP to inspect diverse structured data, such as addresses split across multiple columns (e.g., street, state, country, and zip code). Additionally, this enables Enterprise DLP to detect sensitive data in structured data with a high confidence level regardless of how the data is organized or formatted. Enterprise DLP can process horizontally aligned tables, multiple tables on a single sheet, and combinations of tables and free-form data. This ensures consistent protection across a global data ecosystem.
Enterprise DLP supports structured data processing for predefined data patterns and cloned predefined custom data patterns. Enterprise DLP doesn't support structured data processing for custom regex data patterns.
Enterprise DLP can determine where columns and rows begin and end, which allows it to understand when a proximity keyword and sensitive data are located within the same column or row. Additionally, Enterprise DLP can calculate the character distance between a keyword and sensitive data regardless of their location in structured data.
Enterprise DLP elevates a match to High Confidence for structured data if it meets any of the following criteria:
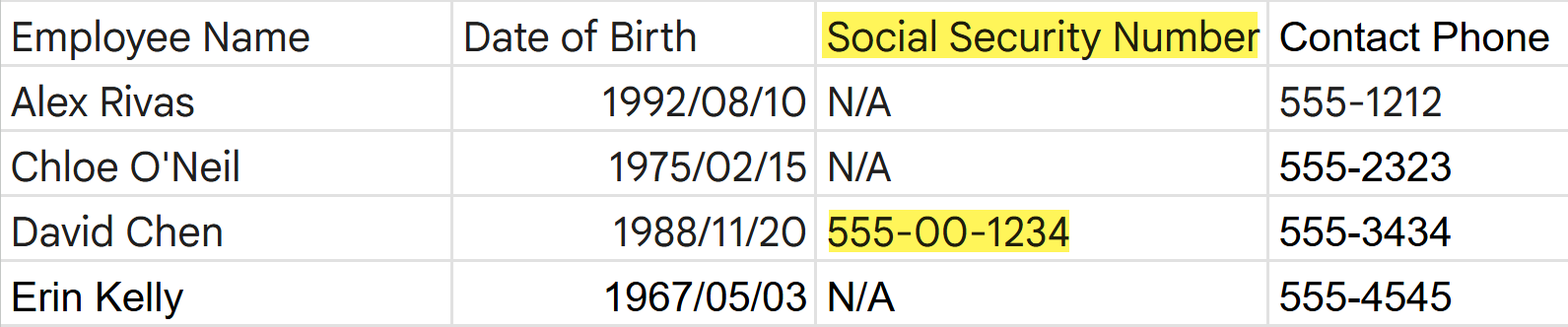
- Proximity Keyword and Sensitive Data Within Proximity Keyword DistanceEnterprise DLP evaluates a traffic match to a High Confidence detection if the sensitive data is within the configured distance of the proximity keyword even when the sensitive traffic match is detected in a different column or row than the proximity keyword. The default proximity keyword distance is 200 characters.For example, consider the proximity keyword Social Security Number and the sensitive data match 55-00-1234. Even though the sensitive traffic match is in a different column and row than the proximity keyword, Enterprise DLP considers this a High Confidence detection because the Enterprise DLP detected the sensitive data within the default 200 character distance of the proximity keyword.
![]()
- Keyword Inclusion in a ColumnSensitive data detected when a proximity keyword is present anywhere within the data column.
![]()
- Keyword Inclusion in a RowSensitive data detected when a proximity keyword is present anywhere within the data row.
![]()
- Detections Exceed 10 OccurrencesEnterprise DLP detects 10 or more occurrences of the same sensitive data type within a single row or column. When this occurs, Enterprise DLP considers all detections of that type in the row or column to be high confidence.
![]()
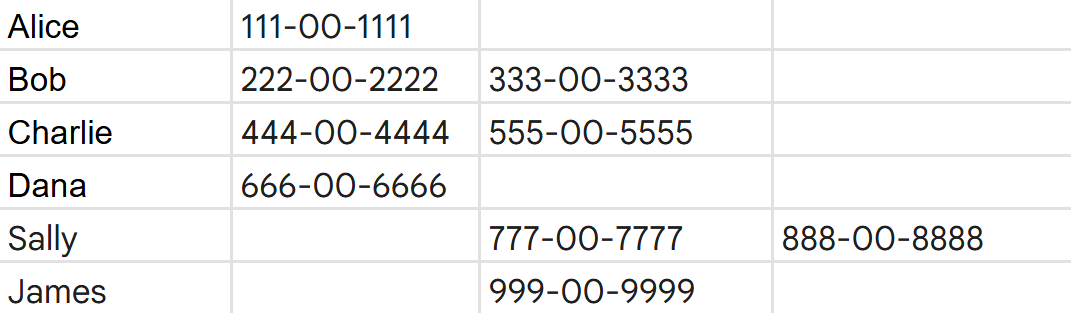
- ClusteringEnterprise DLP uses data clustering to group instances of sensitive data that are close to each other in structured data, such as tables. Enterprise DLP considers a group a High Confidence cluster when six or more detections of the same type appear in a row or column regardless of a proximity keyword. Two detections form a cluster if they are no more than one row or one column apart.For example, assume you have a structured document without multiple columns that don't have column headers. These columns contain clusters of cells with what Enterprise DLP believes to be sensitive data based on their structure.
![]() Clustering is highly advantageous to predict instances of sensitive data where the sensitive data is highly structured and predictable, such as a U.S Social Security Numbers and Credit Card Numbers. However, clustering is not as affective for free-form text, or very unformatted or unstructured data such as a U.S Bank Account Number or a Latvian Drivers ID. Contact Palo Alto Networks Customer Support if sensitive data clusters generates a false positives and you want it disabled on your Enterprise DLP tenant.
Clustering is highly advantageous to predict instances of sensitive data where the sensitive data is highly structured and predictable, such as a U.S Social Security Numbers and Credit Card Numbers. However, clustering is not as affective for free-form text, or very unformatted or unstructured data such as a U.S Bank Account Number or a Latvian Drivers ID. Contact Palo Alto Networks Customer Support if sensitive data clusters generates a false positives and you want it disabled on your Enterprise DLP tenant.


Enterprise DLP considers a match Low Confidence if it does not meet any of the above criteria.
Alerting and Reporting
Enterprise DLP offers multiple ways for your data security administrators to monitor incidents, track configuration changes, and to notify end users when they commit a data security policy violation.
- Enterprise DLP IncidentsEnterprise DLP generates a DLP incident when user traffic contains sensitive data that matches a DLP rule (Strata Cloud Manager) or a data filtering profile Panorama). Use the Enterprise DLP Incident Manager to explore the incident dashboard and view detailed log information for data security policy violations.
- Audit LogsAudit logs provide a crucial history of all Enterprise DLP configuration and setting changes made by data security administrators on Strata Cloud Manager. Enterprise DLP automatically generates audit logs whenever a data security administrator performs supported actions to ensure transparency and audit compliance. Enterprise DLP supports separate audit logging for specific Enterprise DLP channels, including viewing Email DLP audit logs and monitoring Endpoint DLP Push Logs to confirm the successful status of policy pushes to endpoint agents.
- End User Alerting and Coaching (Agent-based vs. Agentless)In modern environments, client-side JavaScript handles many file uploads, which can interfere with the direct display of standard Prisma Access or NGFW block pages. In these cases, the user might see a generic app-specific error instead of the detailed block message. To address this, Enterprise DLP leverages End User Alerting and Coaching to deliver notifications directly to the end user when they generate a DLP incident.NameTypeDescriptionAgentlessIntegrate Enterprise DLP with Cortex XSOAR to provide end users with information about blocked file uploads and enable self-service temporary exemptions.Review the setup prerequisites for End User Alerting with Cortex XSOAR for more information about supported plugin and PAN-OS versions, and apps.Agent-basedEnd User Coaching utilizes Prisma Access Agent or GlobalProtect agent installed on the end user's device to display notifications directly to the user in the Access Experience User Interface (UI) when they generate a DLP incident.Review the setup prerequisites for End User Coaching for supported agent, plugin, PAN-OS, and Prisma Access data plane versions.